大家好,我是 Newt。我目前在鹄望云负责后端服务器的运维和技术支持。每天的工作基本就是在和各种报错日志、硬件故障“死磕”。
就在今天(4月20日),后台报警显示一台宿主机下的 RTX 5090 VPS 突然掉线。当我登进VNC控制台一看,好家伙,满屏幕的 nvidia-modeset: ERROR: GPU:0。这通常意味着显卡已经因为某种极端原因“罢工”挂起了。
作为一名天天和硬件打交道的运维,我意识到这不仅仅是一个简单的死机。今天,我就想结合这次实战,和大家聊聊在 5090 上跑 ComfyUI 多模态流时,那些你不曾注意到的“底层硬件”。
一、 案发现场:26GB+ 显存的“极限挑战”
我迅速查看了该 VPS 掉线前的进程状态。通过 ps aux 的快照可以看到,用户正在运行一个 python main.py 的进程,其虚拟内存申请竟然达到了恐怖的 940GB。
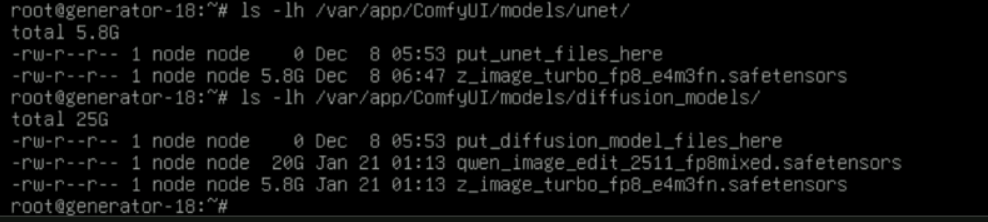
进一步通过 lsof 探针分析,我锁定了罪魁祸首——该用户在 ComfyUI 环境下,同时加载了两个重量级模型:
Qwen2-VL 多模态大模型 (
qwen_image_edit_2511_fp8mixed.safetensors):体积约 20GB。它负责理解用户的视觉指令。Diffusion Turbo 扩散模型 (
z_image_turbo_fp8_e4m3fn.safetensors):体积约 5.8GB。它负责最终的像素生成。
算一笔账: 20GB + 5.8GB = 25.8GB。再加上 ComfyUI 运行时的 VRAM Cache、Python 3.13 虚拟环境的开销,以及 CUDA 上下文的初始化,32GB 的 5090 显存已经被顶到了天花板。
二、 环境拆解:前沿开发者的“高配”组合
虽然显存吃紧,但不得不说,这位用户的环境配置非常超前,很值得 AI 开发者参考:
Python 3.13:目前绝大多数 AI 环境还停留在 3.10/3.11,用户使用了 3.13 显然是为了追求极致的执行效率。
NVIDIA 595.58 驱动:这是目前非常前沿的 Beta 版驱动,是释放 5090 新架构 FP8 算力的关键“钥匙”。
ComfyUI 节点流:通过 Qwen2-VL 赋予 AI “眼睛”和“逻辑”,实现精准的图生图编辑。
三、 避坑指南:为什么你的 5090 会频繁“掉线”?
在排查过程中,我发现导致 5090 掉线(PCIe 链路 rev ff)的核心原因有两个:
1. 瞬态功耗冲击(Power Spikes)
RTX 5090 的爆发力极强。当用户点击“Queue Prompt”开始生图的一瞬间,20GB 的模型数据会在显存中疯狂交换,GPU 功耗会瞬间从待机飙升至 500W 以上。如果电源的瞬态响应不够快,或者主板供电分配不均,显卡就会因为掉压而锁死。
运维建议: 我们最终将这套环境从 X10 主板 迁移到了 X11 主板 宿主机。新主板在高功率设备的支持上表现更为稳健,且我们将功率上限临时限制在 530W,在满血性能与稳定性之间找到了甜点位。
2. “温控”才是生产力
5090 核心热量积累极快。由于用户在进行高强度的模型推理调试,温度极易冲破阈值。
经验法则:当监控显示核心温度超过 80°C 时,建议联系运维开启服务器风扇全速模式(Full Speed Cooling)。
四、 总结:算力租凭时代的极致体验
对于正在寻求 GPU 服务器的开发者来说,5090 不仅仅是数字上的提升,它带来的 32GB 大显存 让以前无法实现的“Qwen2-VL + Flux/Turbo”联动成为了可能。
如果你也遇到了类似“Error while waiting for GPU progress”的报错,不妨检查以下三点:
显存是否已被 20GB+ 的超大模型占满?
功耗限制(Power Limit)是否设置合理?
宿主机主板与电源是否能扛住 5090 的瞬时冲击?
最后,作为一名运维,我也想提醒大家:顶级算力也需要顶级的维护。在高强度生图时,请多关注你的显存占用和功耗曲线。如果你在调试过程中遇到了解决不了的硬件玄学问题,欢迎留言讨论,或者来鹄望云找我“对线”。
本文基于真实运维案例编写,文中涉及模型与环境均为实测数据。
[此处留空图 2:展示 5090 在加载 Qwen 模型时的 nvidia-smi 显存实时占用图]